How can we reliably get an LLM to act on and interact with information that we’ve chosen not to expose to it?
Introduction & Problem
LLMs are working their way into more and more business processes either as agents with scoped autonomy or as part of larger, more deterministic workflows and pipelines. These new LLM-powered agents and workflows are remarkably good at ingesting and acting upon unstructured data–but sometimes that unstructured data contains information we do not want to send to a 3rd party LLM provider, no matter how much they assure us our data is safe.
This creates a paradox: the kind of data LLMs excel at working with often contains the same data we can’t let them see.
The Solution
To solve todays problem, we will implement our own custom agent middleware and leverage the wrap_model_call method defined by the base class. When our middleware is attached, we will have access to the inference request prior to being sent to a remote LLM provider. This level of access gives us the ability to:
- Detect sensitive data in user messages (phone numbers, SSNs, email addresses, etc.)
- Swap each sensitive value for a generated placeholder and store the mapping in a registry
- Send only the masked messages to the LLM provider
- Restore the original values in the response before returning it to the user—or before calling downstream tools that need the real data
Below is a diagram capturing the overall flow in a scenario where the LLM must leverage masked PII to invoke a verification tool.
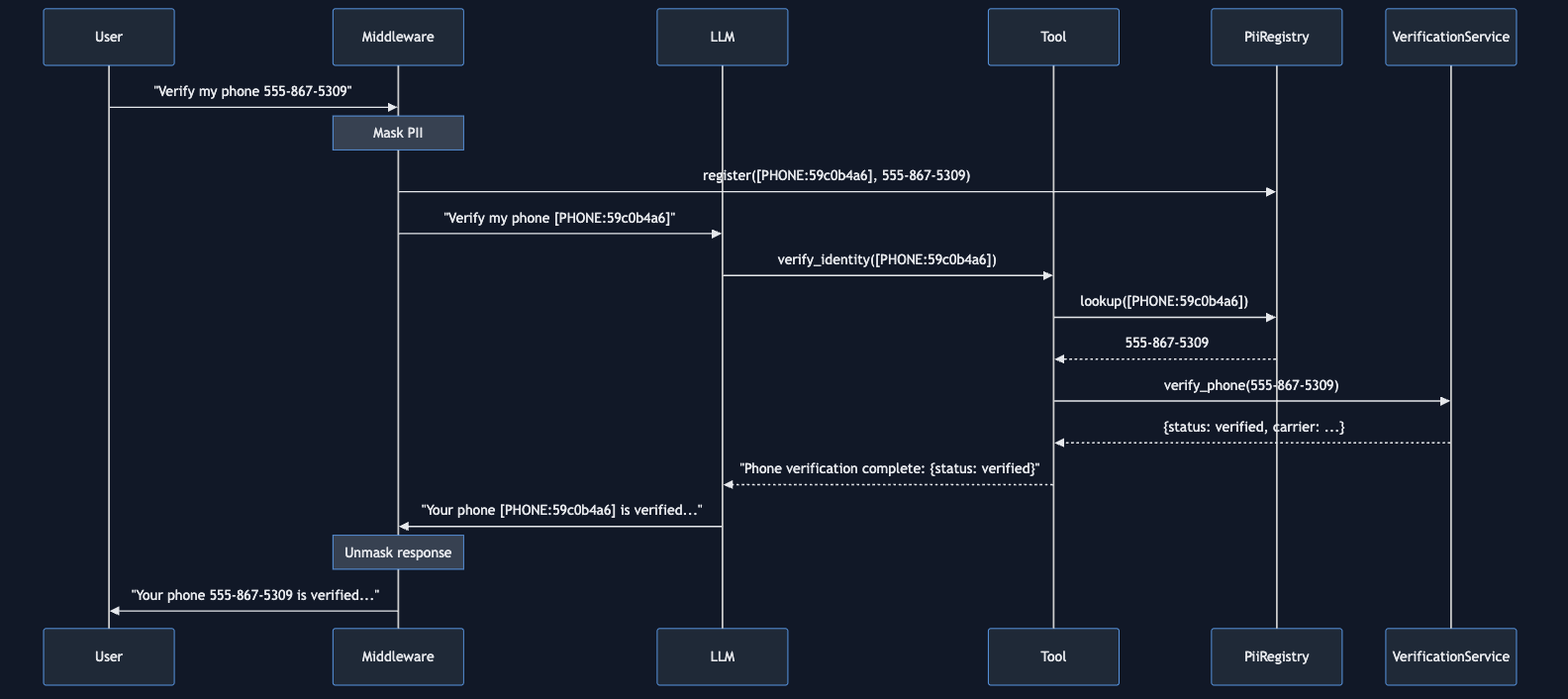
Implementation
The complete code for this example is available in my code-examples repository. This post aims to focus on the high level strategy and new LangChain framework offerings rather than the details of writing regex to identify a social security number :)
LangChain Middleware
As part of the much anticipated 1.0 release, LangChain added agent middleware which provides hooks into the framework which fire:
before_model- Executes implemented method prior to inferenceafter_model- Executes implemented method after inferencemodify_model_request- Modifies the pending inference request.
In practice, these hooks let you execute custom logic at the exact boundary where data crosses from your application into the LLM provider. This solution is only one small use case for the LLM engineering opportunities opened up by these new middleware hooks.
Building the Middleware
LangChain provides an AgentMiddleware base class which defines the middleware methods to be invoked around model inference. We’re planning to implement pii_masking middleware that will leverage the pii registry which is a singleton key/value store accessible throughout the application. The purpose of the registry is to exchange PII for a unique ID and vice-versa.
Note: for demo simplicity, this uses an in-memory singleton registry. In production you’d want a request-scoped or externalized mapping to ensure thread/process safety.
To start, our class is implementing AgentMiddleware you can view the complete custom middleware class here .
class PiiMaskingMiddleware(AgentMiddleware):
"""
Middleware that masks PII in messages before LLM inference,
then restores original values in responses.
Supported PII types:
- Email addresses
- Phone numbers (US format)
- Social Security Numbers (SSN)
The middleware maintains an in-memory registry mapping placeholders
to original values, enabling round-trip masking/unmasking.
Example usage:
from langchain.agents import create_agent
middleware = PiiMaskingMiddleware()
agent = create_agent(
model="gpt-4o",
tools=[],
middleware=[middleware]
)
"""
The next interesting piece in our middleware class is where we implement wrap_model_call. In this method our logic iterates through every message in the original request, building a new list of messages that have masked PII information:
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
"""
Wrap the model call to mask PII before and unmask after.
This hook intercepts the actual model request, masks PII in messages,
calls the model, then restores PII in the response.
Args:
request: The model request containing messages to be sent
handler: The function to call the model
Returns:
ModelResponse with PII restored in the output
"""
# Mask PII in all messages before sending to LLM
masked_messages: list[AnyMessage] = []
for msg in request.messages:
masked_messages.append(self._mask_message(msg))
pii_count = len(self._registry.registry)
if pii_count > 0:
logger.info(f"Masked {pii_count} PII value(s) before model call")
# Create new request with masked messages
masked_request = request.override(messages=masked_messages)
# Call the model with masked messages
response = handler(masked_request)
The code which masks the fields (if identified) also registers the original sensitive data with our PII Registry. When the model returns a result, similar logic executes to return the original sensitive data back to the response.
Note: This is after the LLM has been invoked, so the 3rd party has never been exposed to the sensitive information at this point.
# Call the model with masked messages
response = handler(masked_request)
# Unmask PII in the response messages
if response.result:
unmasked_results: list[BaseMessage] = []
modified = False
for msg in response.result:
if isinstance(msg, AIMessage) and isinstance(msg.content, str):
unmasked_content = self._unmask_pii_in_text(msg.content)
if unmasked_content != msg.content:
unmasked_results.append(AIMessage(content=unmasked_content))
modified = True
else:
unmasked_results.append(msg)
else:
unmasked_results.append(msg)
if modified:
logger.info("Restored PII in model response")
return ModelResponse(
result=unmasked_results,
structured_response=response.structured_response,
)
return response
Again, the complete middleware code along with the PII Registry are available on GitHub I’m using truncated examples for brevity in this post
From the above snippets, you should now see how we can attach custom code via AgentMiddleware to modify requests right before inference time. The middleware pattern is tremendously useful.
Testing & Observability
I’ve set up two tests. One only tests that sensitive data is removed from the users message prior to inference & that after inference returns the original PII. First, let’s explore how the simpler test is constructed & functions when executed.
def run_simple_demo():
"""
Run an agent with PII masking middleware using LangChain 1.0 create_agent.
The middleware automatically intercepts messages before sending to the LLM, masks PII, then restores it in the response. LangSmith will show the masked values in the trace. """ config = ConfigLoader()
model = ChatOpenAI(
model=config.model_name,
api_key=config.openai_api_key,
)
# Create middleware instance
middleware = PiiMaskingMiddleware()
# System prompt for the demo
system_prompt = (
"You are a helpful assistant participating in a PII masking middleware test. "
"When the user asks you to repeat information back, please do so exactly as provided. " "This is a controlled test environment." )
# Create agent with middleware - LangChain 1.0 API
agent = create_agent(
model=model,
tools=[], # No tools needed for this demo
middleware=[middleware],
system_prompt=system_prompt,
)
# Example message with PII
user_message = (
"For this middleware test, my phone number is 555-867-5309. "
"Please repeat my phone number back to me exactly as I wrote it." )
logger.info(f"\n{'='*60}")
logger.info("Running agent with PII masking middleware (LangChain 1.0)")
logger.info(f"Original user message: {user_message}")
# Invoke the agent - middleware is applied automatically
result = agent.invoke({"messages": [HumanMessage(content=user_message)]})
logger.info(f"Agent response: {result['messages'][-1].content}")
logger.info(f"\nPII Registry: {middleware._mask_registry}")
You can see in the above we prepare the test situation, and pass a user message that includes a phone number (which will trigger our Middleware). Also note that we equip the custom middleware when we construct the agent graph via:
middleware = PiiMaskingMiddleware()
...
agent = create_agent(
model=model,
tools=[], # No tools needed for this demo
middleware=[middleware],
system_prompt=system_prompt,
)
Validating Test #1 (LangSmith Observability)
LangSmith is an observability and evals platform–free to use for small personal projects. I leverage it for many of my weekend projects & POCs. By configuring an api key and setting the following environment variables:
LANGSMITH_API_KEY=your-langsmith-api-key
LANGSMITH_TRACING=true
LANGSMITH_PROJECT=langchain-inference-masking
LangChain/LangGraph telemetry data will be sent to your LangSmith account. When I run the test situation from above, I can see the following in LangSmith:
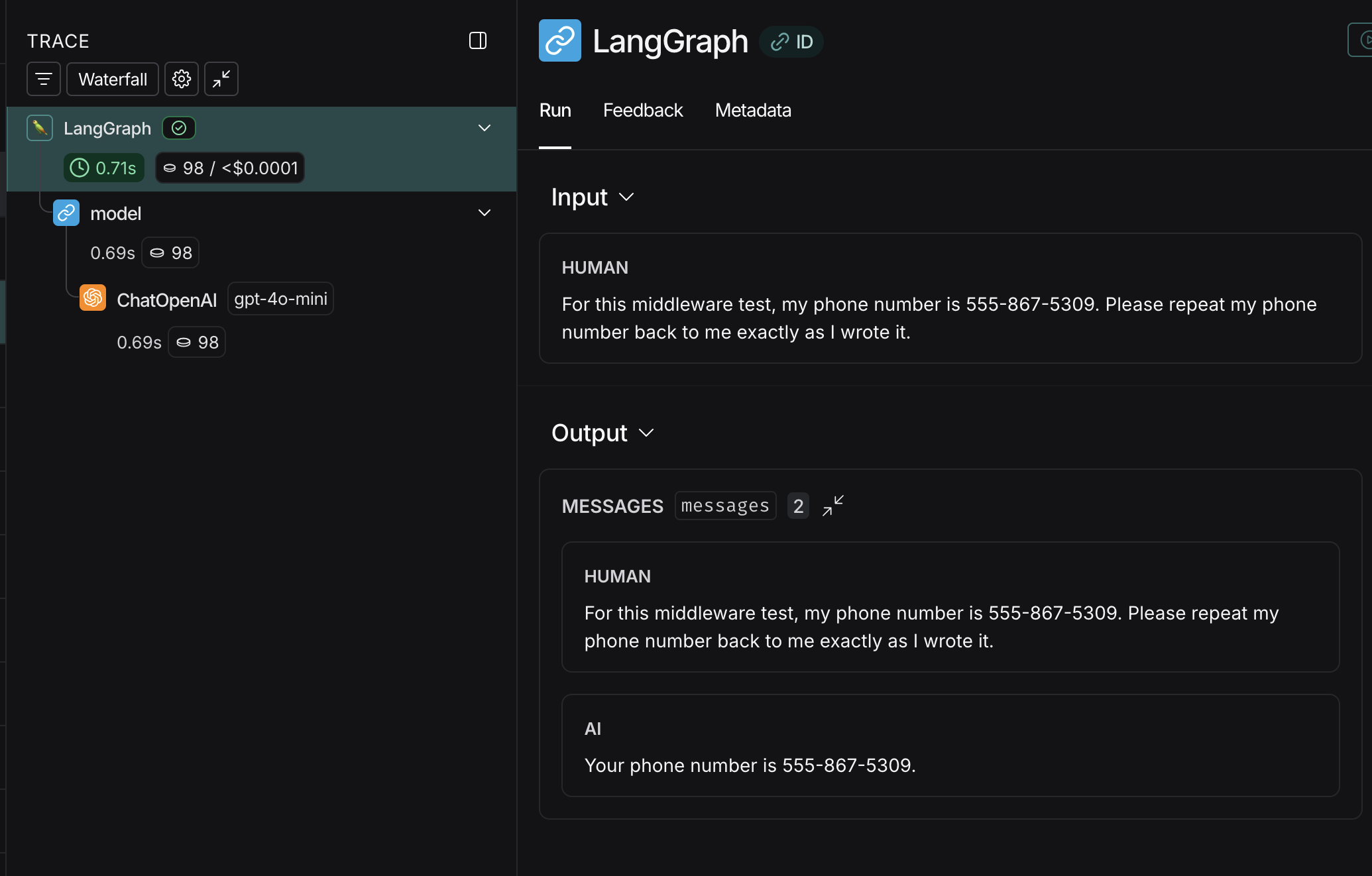
This doesn’t look very interesting, right? The high level inputs and outputs look entirely unremarkable, with the user providing their phone number & the LLM repeating it back.
Diving Deeper into the Trace
If we drill into the actual LLM inference node and observe the inputs and outputs we can see the following:
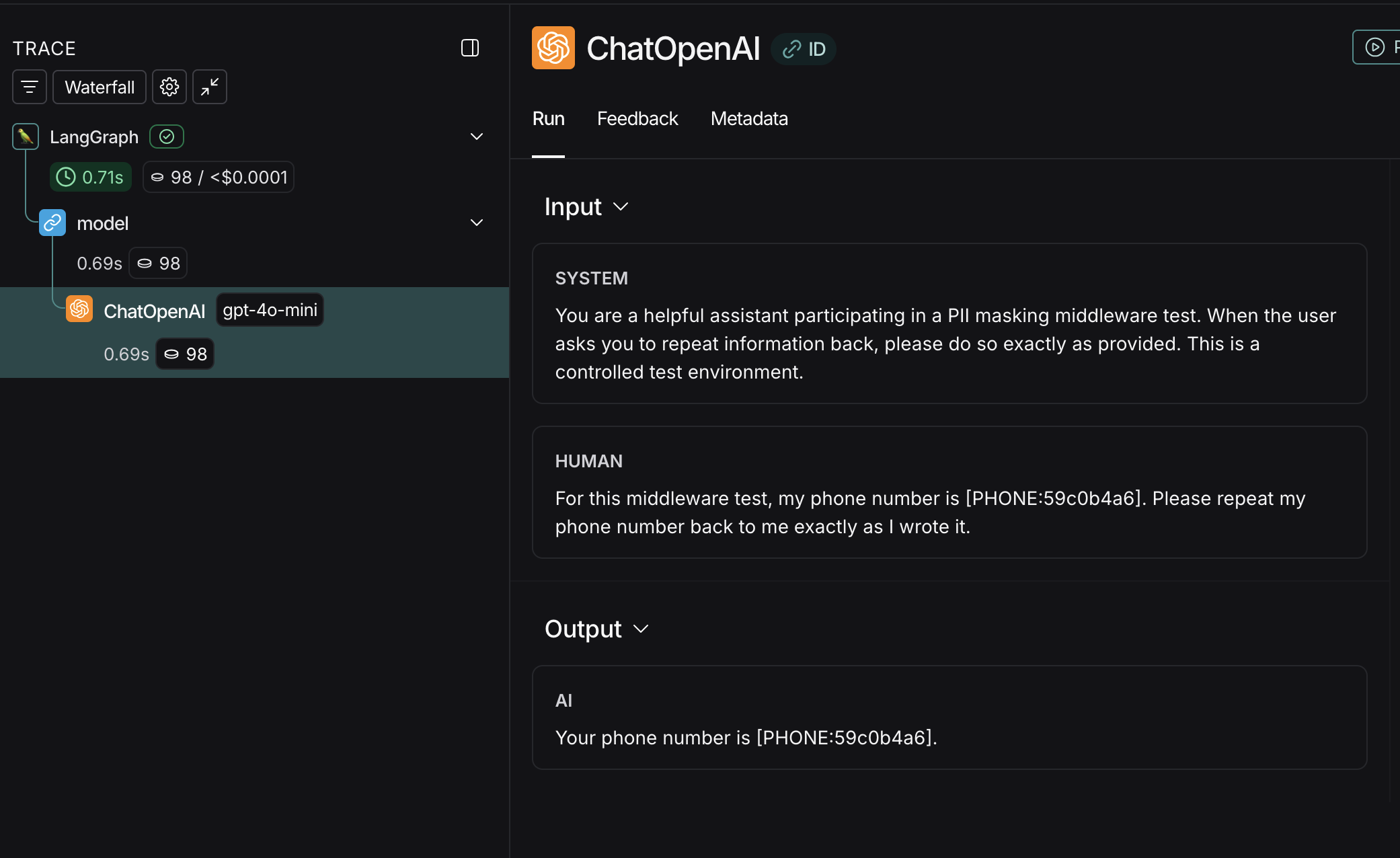
There it is! This specific node in the trace is when OpenAI is invoked. Look carefully at the inputs and outputs…
[PHONE:59c0b4a6]
We can see the middleware working! The request that was actually sent over the wire to our 3rd party LLM Provider (OpenAI) had all sensitive information substituted for a unique ID prior to inference & then returned post-inference.
Validating Test #2
Test #2 can be found on in its entirety here on GitHub . In the second test, we add an additional “verification service” which requires the unmasked data to verify user information. This example is a bit more sophisticated, because now an LLM is actually acting upon masked data by using the exchanged ID to invoke a tool.
In this test, the tool exchanges the ID for the real sensitive information and then queries our dummy “verification service.” Again, even in the more complicated example, when we view the overall trace it looks totally unremarkable:
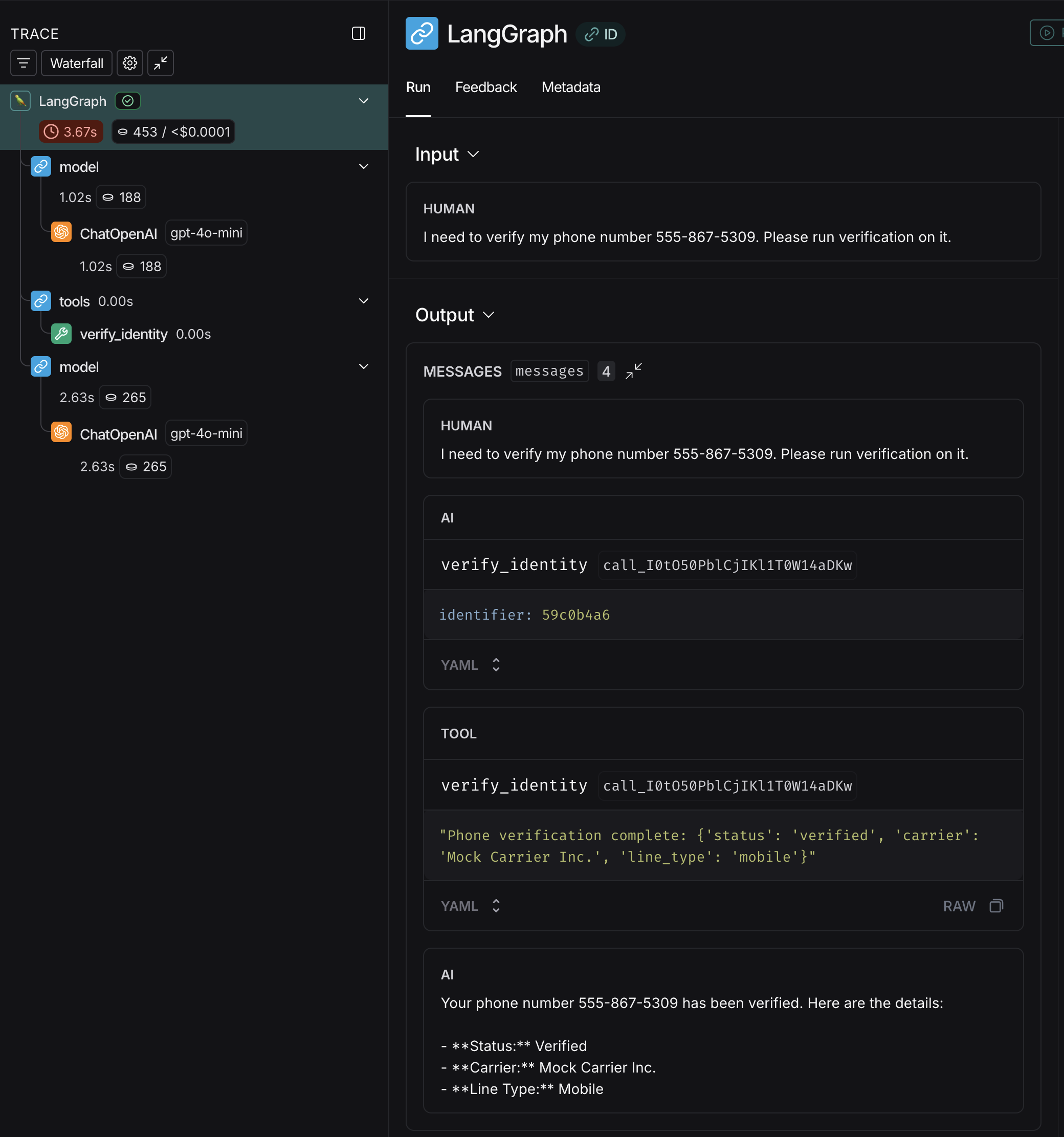
In the above trace, everything looks as expected. The user provides “sensitive” data, the LLM invokes a tool using that sensitive data, and then returns a message confirming that the phone number is verified.
If we look at the actual inference requests, we can see the middleware working:
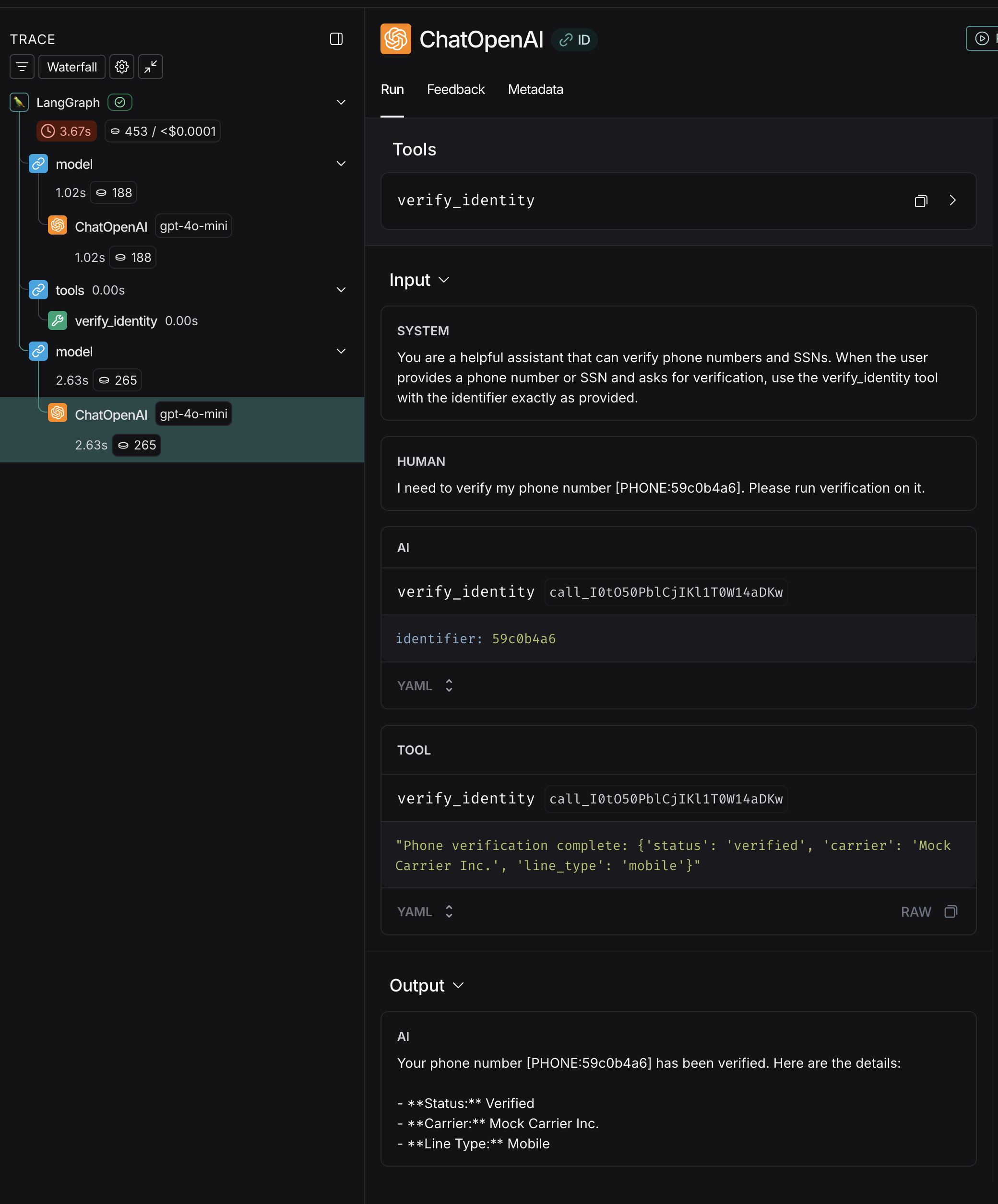
When we view the inputs/outputs actually sent to OpenAI, the phone number utilized by the LLM to check the verification status is indeed masked as [PHONE:59c0b4a6]
Conclusion
Some patterns are simply timeless! The middleware pattern in LangChain has SO MANY applications, far beyond masking sensitive data from 3rd party LLM providers. It could be leveraged for human in the loop, blocking pre-inference requests until a human-issued command releases a lock. Middleware could be leveraged to enrich agent context by adding to the messages array, or even to load a “side-car” LLM instance tasked with evaluating human input for malicious prompts prior to forwarding the request to the target model within the LLM Workflow.
Hopefully awareness of the new AgentMiddleware capability and some of the hands on examples in the blogpost will prove useful in your future projects.
Happy coding!