
With the recent OpenAI announcement adding memory to chatGPT, it seemed like a great time to write about how to add memory to large language models (LLMs). While the OpenAI announcement is new, giving LLMs persistent memory is not.
We will begin by covering the fundamental concepts of memory in LLMs, and then continue discussing some high-level strategies. This post will not include code examples and will be focused on how to conceptualize memory management for LLMs.
It is important to remember that this is a new and rapidly evolving field. The strategies discussed here are not exhaustive. Ultimately, the design of your LLM memory will depend on the specific requirements of your project. This article will set the stage for different types of Request Augmented Retrieval (RAG) strategies to be implemented in the context of extending the dynamic memory of LLMs.
Note: While LLMs are not limited to chatbots, I will be describing the memory strategies in the context of a chatbot to keep things simple.
Conceptualizing In-Context Memory
At this time, LLMs are limited to a fixed-size context window. This means that there is a limit to the amount of information that a model can process at a given time (measured in Tokens). With most LLM providers, the clients will maintain the context and send the existing context along with the latest input to the model.
This can be a long string, but it’s generally easier to envision the context window as an Array of messages between the model and the user.
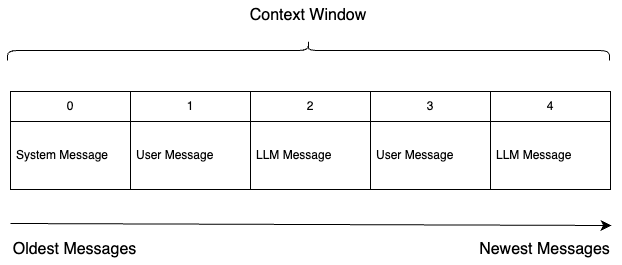
Figure 1: Diagram of a context window
In the above diagram, the context window is represented as an array of messages. The most recent message is at the end of the array. The messages are ordered from oldest to newest. The “System Message” is almost always prevented from being removed from the context window as it will contain critical information to the model–typically profiling instructions that inform the LLM of its roll & desired behavior.
The Context Window memory is the “short term” memory of the LLM. It will typically be managed in memory on the application or on something like Redis.
Sliding Windows
A “sliding window” is a common strategy for managing the context window. This is where the context windows is maintained as a fixed size of messages or tokens. When the context window is full, the oldest message is removed to make room for the newest message.
This strategy is straightforward, but eventually results in the loss of the oldest context messages unless a mechanism is in place to persist them.
Reserved Indices
Before we can attach a persistent memory store to the LLM we will first need a place to put the data. As mentioned before, the context-window for Language Models is limited, so we will need to use a location within the context window to insert information fetched from a persistent memory store. If the application can identify relevant information from the persistent memory store, it can insert it into the context window at a reserved index for the model to use.
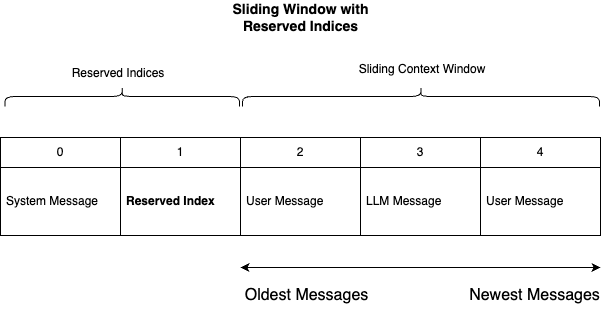
Figure 2: Reserved Indices in the Context Window
In the above diagram, we can see that the context window has been adjusted to include reserved indices. This effectively reduces the size of the context window for unabridged, unreserved messages–but it does provide a placeholder for messages that are retrieved from a persistent memory store.
Note: Some retrieval strategies will simply append the injected context messages at the end of the context window. I have had success with both strategies, but I personally prefer more granular control over the context window.
Persisting and Retrieving Context
When we write code to manage the context window, we can create mechanisms to persist & retrieve data that has been removed from the context window.
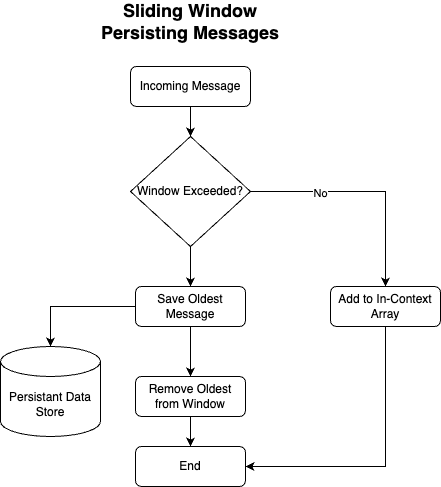
Figure 3: Persisting Context
Above, we can see the high-level approach for an application to balance the management of both “short-term” and “long-term” memory. As the context window fills up, the application can save the oldest messages to a persistent memory store.
Note: As mentioned at the top of this post, the implementation details depend on your use case. The persisted messages could be summaries, they could be converted to vector embeddings, they could be entries in a SQL database or Graph database, etc.
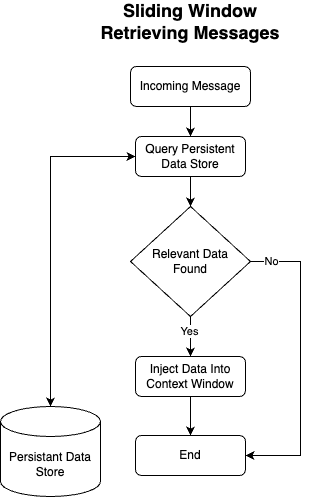
Figure 4: Retrieving Context
Figure 4 demonstrates the flip-side of the equation. When new messages are received, the application can query the persistent memory store for relevant messages and insert them into the context window at the reserved indices.
We finally made it to Retrieval Augmented Generation, or RAG! Above is the high-level retrieval mechanism. The existing context and new message can both be utilized to retrieve relevant information from the persistent memory store. The retrieved information is then injected into the context, giving the model access to a larger pool of information than it would have had otherwise.
Going (a little) Deeper
Now that we have a high-level understanding of memory management for LLMs, we can briefly touch on some more specific strategies in details.
Note: As a pattern, there is nothing stopping us from using an LLM to manage the persistence & retrieval of data. That is to say we can have one instance of an LLM that is responsible for managing the context window and another instance of an LLM that is responsible for having a conversation. I like to think of this as a “subconscious.” That is, a reasoning layer that helps the LLM make decisions about what to remember and what to forget.
- Graph Databases: Graph databases can be enormously powerful, particularly if the use case of your LLM is to manage relationships between entities or concepts. As messages “slide” out of the context window, they can be stored in a graph for the LLM to query later.
- Vector Embeddings: Vector embeddings are a natural fit for LLMs. The messages that are removed from the context window can be converted to vector embeddings. Messages that slide out of the context window are then converted into vector embeddings, stored in a vector database & then retrieved based on semantic relevance to user queries.
- SQL Databases: SQL databases are a great candidate for storing unabridged messages that have been removed from the context window. Code can be written to fetch N number of messages from the persistent data store. An Agent can then evaluate those messages before being inserting into the context window (perhaps the information isn’t useful, or it needs to be summarized).
LLM applications with memory can be designed in a great many ways. If you’re building a autonomous agent instead of a chatbot, the design might be different. Instead of summarizing and retrieving conversation details, it instead might be saving lessons learned instead; For example, if a tool execution fails to align with a plan, the agent can save this information as a lesson to be retrieved before the next planning & execution cycle.
Conclusion
Today we covered the high-level concepts of adding memory to LLMs. We discussed how to conceptualize the context window, sliding windows, reserved indices & request augmented retrieval. We also briefly touched on some more specific strategies and how they might be implemented.
I hope that this article has provided a high-level understanding on how to add memory to LLMs. In future posts, I will be taking a deeper dive into implementing some of these strategies. Feel free to reach out on linkedin the contact page if you have any questions or comments.