AI and ChatGPT have taken the world by storm. Being able to interact with intelligent chatbots unlocks a world of possibilities. Being able to interact with intelligent chatbots that can answer questions based on your own custom data unlocks even more possibilities.
Imagine training a customer-service agent in seconds that knows your product catalog inside out or an interactive run-book that assists engineers dealing with production issues.
Libraries such as LangChain and LlamaIndex have emerged as popular choices for using custom data with chatGPT. These libraries, while impressive, can sometimes be complex and make the underlying principles hard to understand. In this blog post, I’ll try to peel back the layers and explore how to use custom data with chatGPT without using either of these libraries.
10,000 Foot View
OpenAI doesn’t provide a way to use custom data with chatGPT out of the box. As of today it has no mechanism to ingest large volumes of data or train on custom data. The only way to use custom data with chatGPT is to use the API to send a question along with (hopefully) relevant information that the model can use to answer that question.
We will effectively ingest custom data and organize it in such a way that we can fetch relevant information based on the underlying meaning of the text we have stored. Before getting to the code, we will cover some key concepts around how we can retrieve, store and query numeric representations of text.
Key Concepts
Some basic concepts that we need to understand before we can use custom data with chatGPT.
Vector Embeddings
In the context of machine learning, particularly with natural language processing, an embedding is a vector representation of the meaning & relationships of a word or phrase. For example, the word “cat” and the word “dog” are similar in meaning while being entirely different words; These words represented as vectors would be close together in vector space.
Vector Database
A vector database is a database that stores vectors. Vectors can be stored in any type of database, but a vector database will have some additional features that make it easier to work with vectors. Similarity search is a common feature of vector databases and critical for using custom data with chatGPT. With similarity search, we can take a users question and convert it to a vector. We can then perform a similarity search with the vector against our database to see if we have any vectors stored with similar linguistic meaning.
Overview
Today’s project will be split into two fundamental parts: Data Ingestion, where we introduce our data into the system, and Data Retrieval, where we extract this data to use as needed. It is important that we organize our data in a way that makes it easy to ingest and retrieve.
Data Ingestion
For this project, we will be using a simple text file divided into chunks of 200 characters, or ‘text chunks’. We will store the text chunks and vectors in two separate arrays. We will be fetching the vector representation of each text chunk using the OpenAI API.
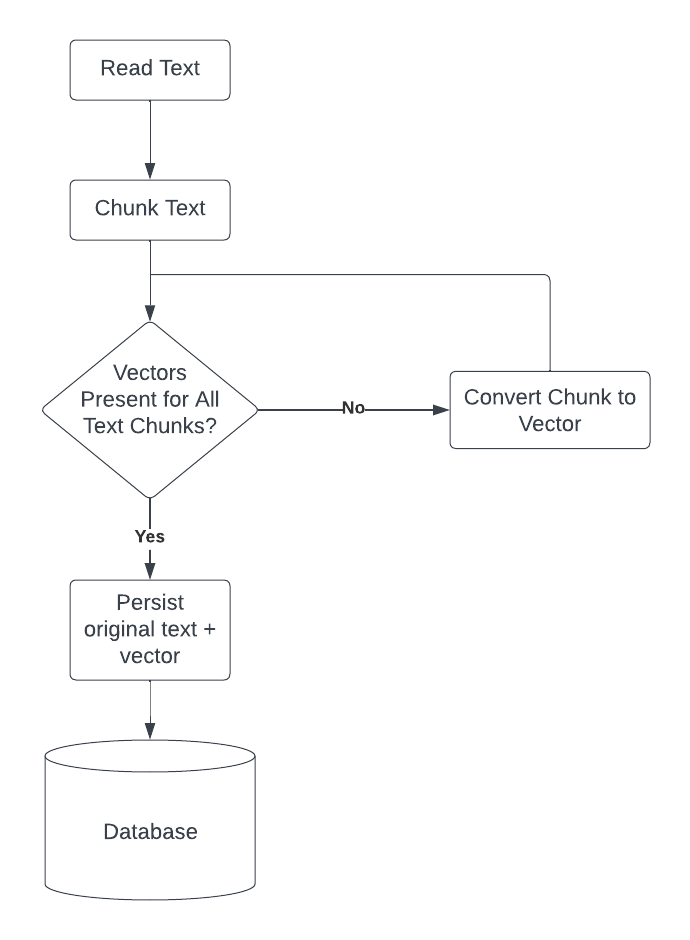
We will be using FAISS to build a vector index from the vectors stored in our vector list.
Data Retrieval
When a user asks a question, we will convert the question to a vector and perform a similarity search against our vector database. We will then use the index of the nearest neighbor vector that was returned to fetch its corresponding text chunk; The text chunk that we extract will be provided alongside the user’s question to ChatGPT, enabling it to answer based on the custom data.
The Code
First we will handle our imports, define an api key and begin writing helper functions.
import os
import openai
import faiss
import numpy as np
# Set up OpenAI API credentials
openai.api_key = '<YOUR_API_KEY>'
###############################################
# Read the text file and split it into chunks
###############################################
def split_file_content(file_path, chunk_size):
# Check if the file exists
if not os.path.isfile(file_path):
return None
# Read the file content
with open(file_path, 'r') as file:
content = file.read()
# Split the content into chunks of specified size
chunks = [content[i:i + chunk_size] for i in range(0, len(content), chunk_size)]
return chunks
The split_file_content function above will read a text file and split it into chunks of a specified size. It will
return an array of strings of length chunk_size sourced from the text file.
###############################################
# Fetch Embeddings for Each Chunk & Store
###############################################
# Function to fetch embeddings and extract vectors for a string
def fetch_embeddings(input_string):
embedding_vectors = openai.Embedding.create(
input=input_string,
model="text-embedding-ada-002"
)["data"][0]["embedding"]
# Extract the embeddings from the response
return embedding_vectors
Above is another helper function that will take a string and return the embeddings for that string. We will use this for both building our vector database with vector representations of the chunks of text created earlier and to convert the user query into a vector for similarity search.
# Split the file content
split_text_content = split_file_content('../data/input_data.txt', 200)
vectors_array = []
# Build an array of vectors for each chunk of text
for split_text in split_text_content:
vectors = fetch_embeddings(split_text)
vectors_array.append(vectors)
Now we have two lists, a vector_array and a split_text_content array. The vector_array contains the vector representations for
each text chunk. These two arrays are also the same size & in the same order so a vector at index 0 in the vector_array will correspond
to the text chunk at index 0 in the split_text_content array.
We are now ready to build the FAISS index and collect user input.
###############################################
# Build FAISS Database for Similarity Search
###############################################
dimensionality = len(vectors_array[0]) # dimensionality based on size of vector array.
# Create an empty FAISS index
vector_index = faiss.IndexFlatL2(dimensionality)
# Convert the list of vectors into a NumPy array
vectors__numpy_array = np.array(vectors_array, dtype=np.float32)
# Add vectors to the index
vector_index.add(vectors__numpy_array)
The code above will build a FAISS index from our vector array. We will use this index to perform similarity search and ideally fetch a chunk of text from custom data that will allow chatGPT to answer the users question.
###############################################
# Ask for User Input / Convert User Input to Vector
###############################################
user_query = input("What is your question? ")
user_query_vector_representation = fetch_embeddings(user_query)
query_numpy_array = np.array(user_query_vector_representation, dtype=np.float32)
###############################################
# Perform Similarity Search
###############################################
k = 2 # Number of Nearest neighbors to retrieve
distances, indices = vector_index.search(query_numpy_array.reshape(1, -1), k)
fetched_context = []
# Append all results to fetched context
for i in range(k):
# Uncomment to see more information about the nearest neighbors & corresponding text chunks
# print("Nearest neighbor", i+1)
# print("Distance:", distances[0][i])
# print("Index:", indices[0][i])
# print("Vector:", vectors[indices[0][i]])
# print("Text Chunk:", split_text_content[indices[0][i]])
fetched_context.append(split_text_content[indices[0][i]])
In the above snippet, I’m iterating through a list of the nearest neighbors returned from the similarity search. I’ve left commented code to illustrate some of the information we have access to during the loop.
Now that we hopefully have all information we need to answer the users question, we can pass it to chatGPT and see if it can use our custom data to answer a question.
###############################################
# Prepare Template & Send Data to AI for Answers.
###############################################
Template = """
context: {context}
question: {question}
"
""".format(question = user_query, context = fetched_context[0])
# Define your conversation history
conversation = [
{'role': 'system', 'content': 'You are a helpful assistant who will answer questions based on context provided. If you do not have enough information from the context reply that you have insufficient information.'},
{'role': 'user', 'content': 'context: In 2020 the Los Angeles Dodgers won the World series.\n question: Who won the World Series in 2020?'},
{'role': 'assistant', 'content': 'The Los Angeles Dodgers won the World Series in 2020.'},
{'role': 'user', 'content': 'context: In 2020 the Los Angeles Dodgers won the World series.\n question: Who won the World Series in 2001?'},
{'role': 'assistant', 'content': 'I do not have enough information from the provided context to answer the question.'},
{'role': 'user', 'content': Template}
]
# Send a message to ChatGPT
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=conversation
)
# Retrieve the assistant's reply
reply = response.choices[0].message['content']
# Print the assistant's reply
print("Assistant:", reply)
Before I run the script, take a look at the sample data here. It’s basically an essay about computer science, but in the middle of it I slipped in the phrase “The quick brown fox jumped over the lazy zebra.”
What is your question? what did the quick brown fox jump over?
Assistant: The quick brown fox jumped over the lazy zebra.
Fantastic! It was able to answer the question correctly. Now let’s try a question that is not in the data.
What is your question? what did the zebra jump over?
Assistant: Based on the provided context, the zebra is being used as an example and there is no specific information about what the zebra jumped over.
An interesting reply…The assistant was able to determine that there was not enough information in the context to answer the question, given the prompt history the assistant is behaving exactly how we would expect. We do not want it making up information or using information that is not in the context that we provide.
Behind the scenes, the script is performing similarity search on the user query and returning the most similar text chunk. To see the exact text chunk that was fetched from our custom data, I’ll add a line of code to print the populated template
Template = """
context: {context}
question: {question}
""".format(question = user_query, context = fetched_context[0])
print(Template)
Now I’ll run the script again and this time we should see the fully populated Template, which will include both our original question and the context (which is a 200 character chunk of text from our custom data) that was used to answer the question.
What is your question? what did the quick brown fox jump over?
context: ancements.
The quick brown fox jumped over the lazy zebra.
The emergence of computer programming languages in the 1950s and 1960s propelled computer science into new realms. Languages like FORTRAN and
question: what did the quick brown fox jump over?
Assistant: The quick brown fox jumped over the lazy zebra.
Now that I’m printing the populated template that’s provided to chatGPT, we can see the exact text chunk that was fetched from a corresponding index in our vector index.
Conclusion
I kept the above example very simple. Our custom data was a very short essay, and we only performed a similarity search to retrieve the nearest 2 neighbors (of which we only used one). In a real world scenario, we would likely have a much larger dataset and could retrieve more than a handful of the nearest neighbors, or perform similarity searches against multiple datasets.
Interestingly enough, chatGPT is great at returning answers that conform to a json schema if you ask nicely. This means that we could easily configure agents that prompt chatGPT and give it information about data sources that we could potentially use and have chatGPT determine which sources of data it should use to answer the users given question.
It is really fun to imagine the possibilities of what we could do with this technology.
Full code example can be found here.